One cannot avoid hearing the word “Hive” when it comes to the distributed processing system. In this article, we will see the hive architecture and its components
What is Hive?
Apache Hive is nothing but a data warehouse tool for querying and processing large datasets stored in HDFS. It uses the MapReduce processing mechanism for processing the data. Hadoop framework will automatically convert the queries into MapReduce programs
What language does hive use?
Hive uses HQL – Hive Query Language. HQL follows MySQL standard for syntax checking.
History of Hive
Hive was initially developed by Facebook and then it was contributed to the community. Facebook developed hive for its data scientists to work with a SQL like a tool. You need not have great programming skills to work with hive. Anyone with knowledge of SQL can jump into hive.
Is hive a database?
Many people consider hive as a database management system. But, the truth is different. Apache hive itself is not a database. Consider hive as logical view of the underlying data in HDFS. It cannot store any data of its own. It always uses HDFS for storing the processed data. The only thing it can do is enforcing the structure in which the data can be stored in HDFS.
Ok, now it is clear that hive is not a database. So, how it will maintain its metadata, objects, user details, etc? This is the million-dollar question that will come when you start learning hive. We will see that while exploring the hive architecture below.
What is hive metastore?
Hive cannot store the data it is processing or its metadata either. Hive uses another RDBMS to maintain its metadata. This is called hive metastore. Whenever the hive service is started, it uses a configuration file called “hive-site.xml” to get the connection details of that RDBMS and pull all of its meta-information which includes its tables, partitions, etc. All the required meta-information from the metastore will be reloaded whenever hive service is restarted.
What are hive properties?
Apart from the DB connection details, there are so many properties that will be set in the configuration file. These configuration properties will decide the behavior of the hive. For example, the properties can be set to run hive queries in a dedicated queue with more privilege, the properties can be set to prevent hive from creating dynamic partitions.
Sample hive-site.xml file
<?xml version="1.0" encoding="UTF-8"?> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost/metastore</value> <description>the URL of the MySQL database</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <property> <name>hive.exec.parallel</name> <value>false</value> <description>Whether to execute jobs in parallel</description> </property> <property> <name>hive.exec.parallel.thread.number</name> <value>8</value> <description>How many jobs at most can be executed in parallel</description> </property> <property> <name>hive.exec.rowoffset</name> <value>false</value> <description>Whether to provide the row offset virtual column</description> </property>
Once the metastore setup is done, we can start using the below command “hive –service metastore“
Hive architecture
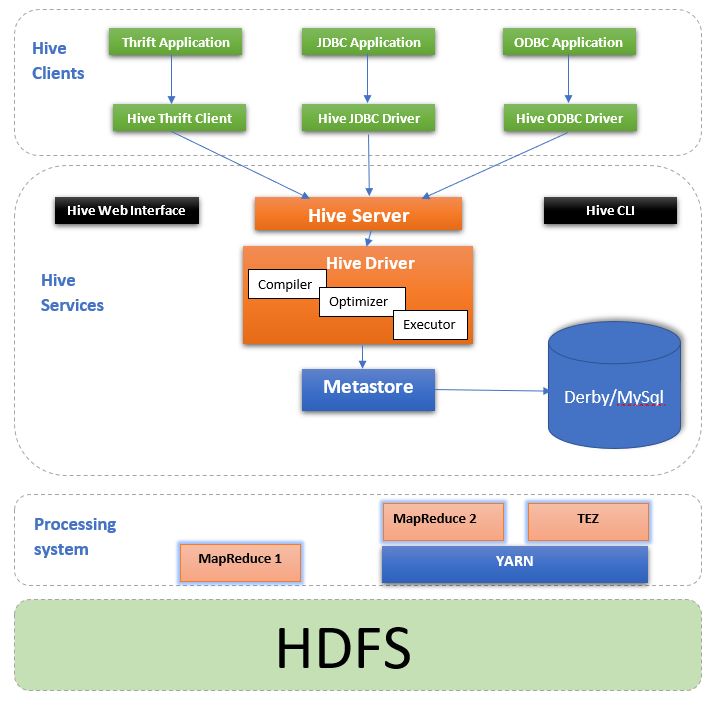
Hive Services
HiveServer/Thrift Server
HiveServer is a service that allows a remote client to submit a request to hive. The request can be coming from a variety of programming languages like java, c++, python. HiveServer is built on Apache Thrift so we can also call it as Thrift Server. Thrift is a software framework for serving requests from other programming languages that supports thrift.
The different client applications like thrift application, JDBC, ODBC can connect to hive through the HiveServer. All the client requests are submitted to HiveServer only.
Hive CLI
The CLI is the most commonly used one for connecting hive. Developers can submit their queries to hive through hive CLI. For accessing hive CLI, the client machine should have hive installed in it. Once installed, you can access hive by running “hive” from the terminal.
Web Interface(HWI)
Hive web interface(HWI) is a GUI to submit and execute hive queries. For running through the web interface, you need not have hive installed in your machine. A developer can open the URL in multiple windows to run multiple queries in parallel. Another advantage of HWI is that you can browse through hive schema and tables.
Hive Clients
- Hive Thrift Client – Hive thrift client supports different types of client applications to interact with hive using different programming languages for data processing.
- JDBC Application – Any JDBC(Java DataBase Connectivity) application can connect with hive using the Hive JDBC driver.
- ODBC Application – ODBC(Open DataBase Connectivity) clients can also connect with hive using the hive ODBC driver.
Hive driver
The hive driver will receive the requests submitted from HWI or CLI. Internally, the hive driver has three different components. Let us check them one by one.
- Compiler – The compiler will check and analyze the query sent by the hive driver.
- Optimizer – The optimizer will generate the optimized logical plan in the form of MR tasks.
- Executor – The executor will execute the query that it receives.
Process and Resource management
Hive used the MapReduce framework to execute the queries. The request will be executed by MR1 in Hadoop1. In Hadoop2, the request can be executed by MapReduce and TEZ engine as well. But, both will be submitted into YARN for execution. YARN will negotiate to get the required resource for running the queries.
Storage
Hive does not have its own storage mechanism. It uses the HDFS for storing the processed data. The output format and delimiter of the table will decide the structure of the file.
Hive supports multiple input formats and compressed forms of the same. Some of the input formats supported by hive are text, parquet, JSON.
Also check, “Hive installation steps“
References – https://en.wikipedia.org/wiki/Apache_Hive